

I am often asked what I do in life and I’m not able to give a clear answer.
Not because my work is fuzzy, but because it’s based on concepts that most people do not understand. The least technical way I explain what I’m working on is:
“I’m in charge of putting into production”.
Certainly, but what is a “production”? It is not a complicated notion but it is a notion that is based on many other concepts that make its explanation quite difficult.
Moreover, we do not really answer the question, to know what “putting into production” really includes.
I also talked a lot with developers I meet and I realized that few of them are interested in my area of expertise. It’s just not their job.
To go further, I take care of the production in the broad sense. And this includes the following areas:
- Architecture of the solution
- Transition from development to production (deployment pipeline)
- Maintain Operational Conditions
- Security
- Disaster Recovery
And each of these areas deserves further development to explain the ins and outs. Each of these notions is based on other, more technical ones.
We will try to skim over each of these points in this article.
Architecture
To make it accessible, I will start from the presentation of a common case: an application containing a backend and a frontend. In our example, the application will be used to find restaurants.
To do this, the company will have to develop several elements:
- A database to store the addresses and specificities of each restaurant
- A backend, the heart of the application that will make research, register new restaurant, etc …
- A frontend, the visible part for the end user, often in the web browser or a mobile application.
Architecture is the part of the work that will allow us to draw the following diagram:
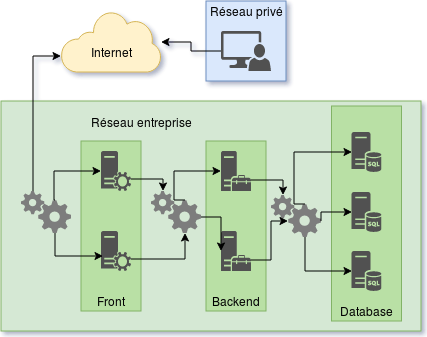
We see that for this small application, we already need 7 machines, configure network layers and provide redundancy services.
This remains a very simple example, it is quite common to be faced with twenty services spread over 30 to 40 machines.
Of course, all companies do not implement all this complexity from the first line of code. You have to make trade-offs and know what is important for the service to be properly delivered to the end user.
Just by looking at this diagram, I have already a dozen ideas to complete the architecture. So this is the first part of my job, think about the system as a whole to see the strengths and weaknesses of the solution.
Industrialization
Once we have our architectural scheme, we have 30 machines running 20 different services… how do we maintain all this? How do we evolve?
From a technical point of view, it would be enough to connect to the machines to configure them correctly, one by one. This is a way of doing that I often meet in companies and unfortunately, this is not the right solution.
Connecting to the machines to configure them by hand gives configurations in snowflakes. Because it’s done by hand, even if we want all our machines to be configured in a similar way, there are always small differences between them. All machines are the same, but not quite #SameButDifferent
Consequences of this are disastrous: put in production is difficult as hell under these conditions. Each machine must have a different treatment, putting in production can take days and we are never sure to get something out of it.
Industrialization is therefore the second part of my work, and I would say the most important. This is a fairly long process, which requires investment in both duration and means. The added value is not immediate so it is not always the priority of companies.
By industrializing, we automate the creation of images. Because, connecting to machines to update them involves risks, so we create images instead.
An image in this context has nothing to do with the images found on the internet in png or jpeg formats. This is an “instant picture” of a machine already configured and ready to use. Thus, when we deploy a machine with our image, it is ready to deliver the service that is expected of it without the need for manual operation.
Then, we automate the replacement of old images with new ones, to ensure a smooth transition in production, with the least possible downtimes.
And this will especially allow to press the button “go for production” with peace. This is thanks to the tests of each of our images. This is where our production pipeline is important.
The pipeline is the concept of a production line, a bit like car assembly lines. Our chain starts with the work of developers who will propose new features. Then those features will be tested and approved by other developers. Then it will go through the step of creating our image, which will serve to create a qualification environment. This environment will allow customers to validate the feature before validating the release.
The main idea behind industrialization is therefore to create a production line that allows the company to:
- Deliver customers faster
- Improve reliability of deliveries
- Banalize delivery (more frequent, faster)
- Be able to validate or invalidate new features more quickly
Even if, at first glance, the establishment of this software factory may seem complicated, the added value is undeniable. I have never seen a company regretting having invested in the industrialization of their platform.
In many cases, the company is not aware that it could invest in industrialization.
Maintain production in operational conditions
Putting into production is fine but life does not stop there. Despite several years of dealing with different software platforms, I am always amazed by the amount of things that can go wrong, especially in production environment.
But once the application is in production, we must maintain it in working order. A stopped production is a loss for the company. The application can only bring money to the company if it is available to its end users, its customers. We must therefore distinguish several possible states:
- Optimal operational conditions, customers have no trouble connecting.
- The deteriorated conditions, there are some delays, some disconnections. This state is very frustrating for the user.
- Shutdown, production is no longer accessible, no more customers can connect.
So we talk about maintaining in operational conditions. It’s a pretty way of putting it, but incorrect in my opinion. In reality, we can not really guarantee to stay in optimal conditions all the time.
However, what we can do is recover an optimal state when an alert is raised. When a machine stops, if the architecture is solid, the service will remain available but in degraded mode.
Degraded mode is better than no longer having service. The goal is to find a fully operational state to ensure a good experience for users.
The good news is that by industrializing the start of production, creating new machines to replace broken ones is easy and fast. However you have to get the information that something is wrong in order to take actions.
Here is the third aspect of my work, keeping the best possible conditions in production, also called monitoring and supervision. It’s about setting up tools to receive alerts if something goes wrong on our system.
But, we can go further than just receive an alert and wait for a technician to do something, we can automate the repair: We dismiss the machine “sick” (we keep it to understand the error), then we starts a new machine that works and finally we start all healthchecks
Healthchecks are the equivalent of unit tests under development. These are small programs that can ensure that the service is in good health.
It is quite difficult to automate this part but if the industrialization went well, monotiring and supervision will be fine too.
Security
Our product is deployed in an industrial way and it self-repairs in case of problems. Everything is awesome !
But there are things I did not talk about. It is difficult to make a separate section to talk about security because it is not a project that can be added, there is no miracle recipe to secure what already exists.
We must have security in mind in all the previous steps. We must always have an eye on this aspect. From development to production, every effort must be made to ensure that important data are protected, encrypted and isolated.
Let’s start with encryption. It is about transforming a message so that nobody can read it and your application will then be the only element to be able to decipher it. Thus, if an attacker manages to intercept data, he will not have the ability to read them and therefore have no way to exploit them. If this topic interests you, I recommend this article: HTTPS with carrier pigeons
Then, what is important and that few companies put in place is the hiring procedure and the departure procedure. When a new colleague arrives, how are we given access to all the tools? How do you do when you leave the company?
Many security flaws arise from this part. Few companies are able to list precisely who has access to the different tools they use and some people are able to act on their productive environments without the company having explicitly agreed.
Finally we have to keep the tools that we use frequently. One of the benefits of industrialization of releases is that we can apply updates more often and be less vulnerable.
However, the problem of computer security is that it remains very illusory. You can never really be sure of your own safety. We can only reduce the risks.
Security is part of my job, through all the services I offer.
Survive cataclysmic events
I told you about what we can put in place to have a production that holds up. And that’s how we get to the last aspect of my work, disaster recovery, or the art of surviving the apocalypse.
Well, OK, in the event of a meteorite fall that would end humanity, your production may be not a priority. But when an excavator pulls the fiber optics out of your datacenter, the production will just not be accessible.
Concretely, you can overcome this kind of event easily if you have done correctly your industrialization. It will just take time to restore normal operating conditions.
The goal here is to stay proactive, predict the worst cases imaginable and become aware of the probability of this kind of event. Losing a datacenter does not happen every day but unfortunately it is frequent enough that I have to endure about 2 per year. I do not count the ones I hear about but do not affect the services I work on.
There is not much to do when the infrastructure itself breaks under your feet, as solid as your installation is, you will be a victim.
But instead of giving up and praying, we can prepare for it:
- Imagine potential disasters
- Assess the risks of each
- Assess the potential impact on your production
- Prepare for impact
These painful events are theoretically rare but believe me, it happens, and more often than we think. Preparing for it is a bit like taking first aid training in the background, we hope we never have to use it but when we need it we are happy to have made the effort to take these courses .
Conclusion
I recently realized that this whole universe of skills was completely foreign to the people I meet. They continue to ask me, even after several years, “But concretely, what is your job? “.
It was this recurring question that made me decide to write this article. I think I’ve done a quick tour of my work here, clarified some of the things I’m working on.
As I said at the beginning, explaining what I’m doing is a small challenge in itself.
Meeting someone, not knowing their affinities with the computer world and explaining my work is a recurring problem.
Every point that I mentioned in this article could be the subject of other articles, without counting the notions that I did not address such as the DevOps culture, methodologies that we put in place with the development teams or networks related issues.
I hope that following this article, you will have a better vision of what can be a website or a mobile application in the background.
I will write other articles in this style, to clarify the concepts that we work on every day.
See you soon,